
“十四五”期间,为加强公共数字文化建设,推动公共图书馆智慧化转型,文化和旅游部面向全国公共图书馆系统组织实施了全国智慧图书馆体系建设项目。按照全国智慧图书馆体系建设任务要求,陕西省图书馆依据《国家图书馆智慧图书馆知识资源数据建设指南》,选取馆藏民国报纸中文献研究价值、读者调取利用率较高的报纸资源,在完成资源精细化标引的基础上,对各类资源进行重新聚类,形成主题化、专题化的分类揭示,利用语义网、大数据、人工智能等技术形成智慧化知识图谱,同时开展对基础数字资源的细颗粒度内容标识、关键知识点的标签和标引建设,精细化揭示进行资源内容,实现了资源的知识化、专题化服务。
为高质量推进项目实施的同时,陕西省图书馆积极探索公共图书馆智慧化管理和服务创新性做法,开发并建设“民国报纸知识资源细颗粒度文献数字化平台”(以下简称平台)。平台在实现基本建设成果展示的基础上,通过先进的知识图谱技术,还可以完成对细粒度文献知识关系的呈现及数据文献的关联和在线查阅。能够对知识资源细颗粒度建设和标签标引文献进行数据保存、管理、检索和综合展示,实现智能化知识发现。
随着信息技术的快速发展,包括图书馆在内的各类公共文化服务机构产生了大量的数字化数据,其中包括文本、视频/音频信息、图像等的非结构化数据约占到总数据量的90%左右。如何对这些非结构化数据进行精准梳理,使之转变为管理科学规范、调用迅速有效的结构化数据,为广大读者提供高效、快捷的人性化、专业化、智慧化的服务,最终实现智慧化管理和服务,已经成为亟待解决的重要课题之一。本平台的开发建设,是对这一难题的积极有益探索。通过开展知识资源细颗粒度建设和标签标引,制作完成的馆藏特色数字资源数据可部署在本地服务器及互联网端进行长期使用,为广大民众提供长期的信息获取服务、个性化、智慧化服务。
(一)项目建设内容及实施过程
1.建设内容
在陕西省文化和旅游厅指导下,陕西省图书馆深入挖掘本馆资源建设开发潜力,通过对馆藏自有版权资源的详细调研分析,明确了资源类型和特点。民国时期的历史文献多以时事新闻和评论为内容,与当时重大历史事件紧密联系,是对当时社会政治、经济、军事、文化巨大变迁的客观反映,具有重大的历史文献研究价值。陕西省图书馆馆藏民国陕西地方报纸61种,其中《西京日报》《西京平报》《解放日报》等重要大型报纸保存较为完整。由于民国时期机械造纸技术和印刷工艺尚不完善,早期流通使用及保存条件有限,民国报纸大部分老化现象严重,亟待进行文献保护和利用。《西京日报》作为一份具有重要历史价值的报纸,记录了西安乃至西北地区的历史事件、社会动态和文化活动,是研究地方历史不可或缺的资料,同时也是陕西省图书馆馆藏民国报纸中藏量最大、体系最完整的报纸资料。因此,2022年至今,重点围绕馆藏《西京日报》开展平台建设。本项目选取《西京日报》1933年3月21日正式创刊至1949年4月15日止所发行的报纸共计约2.6万版进行细粒度标签标引建设,累计完成25.9万条数据。
项目建设参照《智慧图书馆知识资源数据建设指南》标准执行,进行了细粒度文献篇章、主题词及关键词标签著录标引,完成基础资源著录、细粒度文献著录、知识内容抽取标引及知识图谱的构建。
在建设要求上包含了对象数据调研与分析:对馆藏自有版权资源进行详细调研,明确资源类型、分析资源特点。元数据调研与分析包括对已有元数据的著录情况进行调研,明确已有元数据的著录颗粒度、主题标引等情况。
加工规则制定按照国家图书馆关于“知识资源细颗粒度建设和标签标引”《智慧图书馆知识资源数据建设指南》规则规范,对基础数字资源的结构单元,标引字段、细粒度文献著录、知识内容抽取规则以及知识图谱呈现方式进行分项实施。
2.实施过程
(1)制定流程
在准备阶段,通过分析和梳理建设指南要求,明确资源的结构单元和著录粒度,制定了报纸知识资源细颗粒度文献建设的标准化流程。主要包含基础资源著录、细粒度文献著录、知识内容抽取标引及知识图谱构建等内容。严格按照国家标准建设指南的建设要求,对加工的对象数据进行标准化、流程化的实施过程管理。严格把控项目进度,多节点、多阶段工作成果提交,随时查看开发进度。
(2)数字化加工采集
根据指南建设标准进行数字化扫描工作。对民国报纸数字化加工流程每一道工序严格把关,保证了数字化民国报纸加工成果的质量。
①加工前准备工作:先对报纸进行清理除尘,如有透背叶字迹,有虫蛀、漏洞时,需垫上适用的衬纸后扫描。
②根据国际色彩协会(International Color Consortium,简称ICC)标准,做加工设备的基本色彩校正,逐版扫描,分辨率600 dpi,TIFF 不压缩。
③纠偏处理:对出现偏斜的图像进行纠偏处理,图像歪斜度不可以超过一度。
④去污处理:对图像页面中出现的影响图像质量的黑边等进行去污处理。
⑤图像文件加工:图像文件放大到1:1状态,逐版检查。若不符合图像质量要求应进行图像校正或重新扫描;同种报纸图像尺寸相同,不得有失真现象;按版次顺序由小到大,符合阅读习惯,不能有缺版、错版、数据内容缺失等现象(原件有缺失的除外);图像符合扫描规格要求和技术参数;所有文件保存位置以及文件命名正确,可以有效打开和显示。
⑥双层PDF加工:将处理完成后的图像进行报纸篇目文字识别校对。采用图在文上的模式进行双层PDF输出。
(3)分步实施
对基础数字资源的结构单元,标引字段、细粒度文献著录、知识内容抽取规则以及知识图谱呈现方式进行分项实施。
基础资源著录【对象数据命名(民国报纸PDF)——报纸数字化识别——基础文献元数据著录】;细粒度著录【细粒度文献著录(人物、机构、地名、事件、专题标引),图表细粒度著录】;知识内容抽取——元数据生成及存储——知识图谱构建。
(4)标引信息
①基础数字资源著录:基础文献记录标识号、正题名、出版日期、卷期、版次、中图分类、主题词或关键词、出版者名称、出版地、内容形式、媒体类型、格式、语种、适用对象、出版频率、馆藏范围、数据提交单位、所属任务年份。
②细颗粒度文献著录:记录标识号、基础文献记录标识号、出版日期、起始页文件名、结束页文件名、对象文件路径、结构类型、语种、正题名、并列正题名、其他题名、栏目名称、责任者、责任方式、责任者单位、内容、附注、版次、摘要、分类号、关键词、人物名称、机构名称、地理名称、事件名称、图表记录标识号、图表数量。
③知识内容抽取标引:利用自动化手段分析文献内容,建立知识抽取模型,确定知识抽取方法,从馆藏民国报纸中抽取人物、机构、事件、地理名称以及其他具有标目意义的内容,开展知识标引工作,以形成基于文献知识内容的语料库。
a.人物标引:记录标识号、基础文献记录标识号、人物通用名称、人物异名、性别、时代、出生年、卒年、国别、籍贯、民族、亲属关系类别、亲属关系人物、非亲属关系类别、非亲属关系人物、传略、任职机构、职务名称、任职时间段、著述、附注。
b.机构标引:记录标识号、基础文献记录标识号、机构中文全称、机构英文全称、机构简称、地址、前置机构、后置机构、存续开始时间、存续结束时间、行业类型、机构描述、重要人物名称、重要人物事迹、重要事件、重要成果。
c.事件标引:记录标识号、基础文献记录标识号、事件中文全称、事件英文全称、事件简称、事件开始时间、事件结束时间、地点、事件类型、事件描述、重要人物名称、重要人物事迹、重要成果。
d.地名标引:记录标识号、基础文献记录标识号、地域专名、地名简称、异名、行政层级、起始年代、结束年代、沿革事件类型、时间、说明、规范性文件、隶属、辖区、经纬度、参考方位。
e.专题标引:专题标引指从基础数字资源对象内容中挖掘知识内涵明确标引内容,开展特色突出、内容丰富的专题标引。在本次项目建设中会根据民国报纸的实际内容确定标引内容。
(5)展示平台
利用多媒体交互技术、Neo4j数据库和D3.js知识图谱技术,基于B/S架构模式,对大量细粒度文献数据进行可视化交互呈现和文献关联展示。并能够对报纸原貌进行完整呈现和内容定位。同时,设计了能够对大规模数据进行简体、繁体检索的检索引擎,以便于用户进行信息的快速检索和查询。
(二)项目功能作用及技术应用
1.功能作用
平台能够支持文献资源的类别管理、导航树维护、数据的增、删、改、查等功能。前端成果能够通过后台进行统一维护和管理,基于B/S架构模式,兼容多种主流浏览器进行在线访问。采用的知识图谱技术,能够对大量细粒度文献数据进行可视化交互呈现和文献关联展示。

(1)信息检索:平台检索系统支持大规模数据简体、繁体检索。支持对检索结果进行统计。
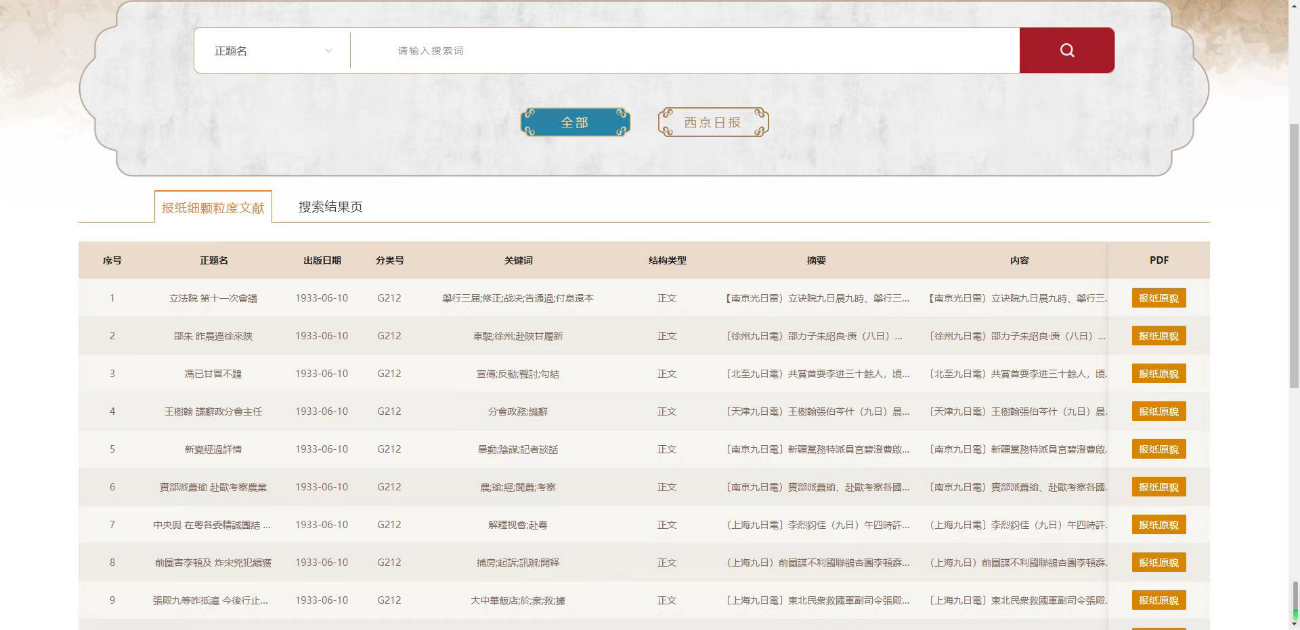
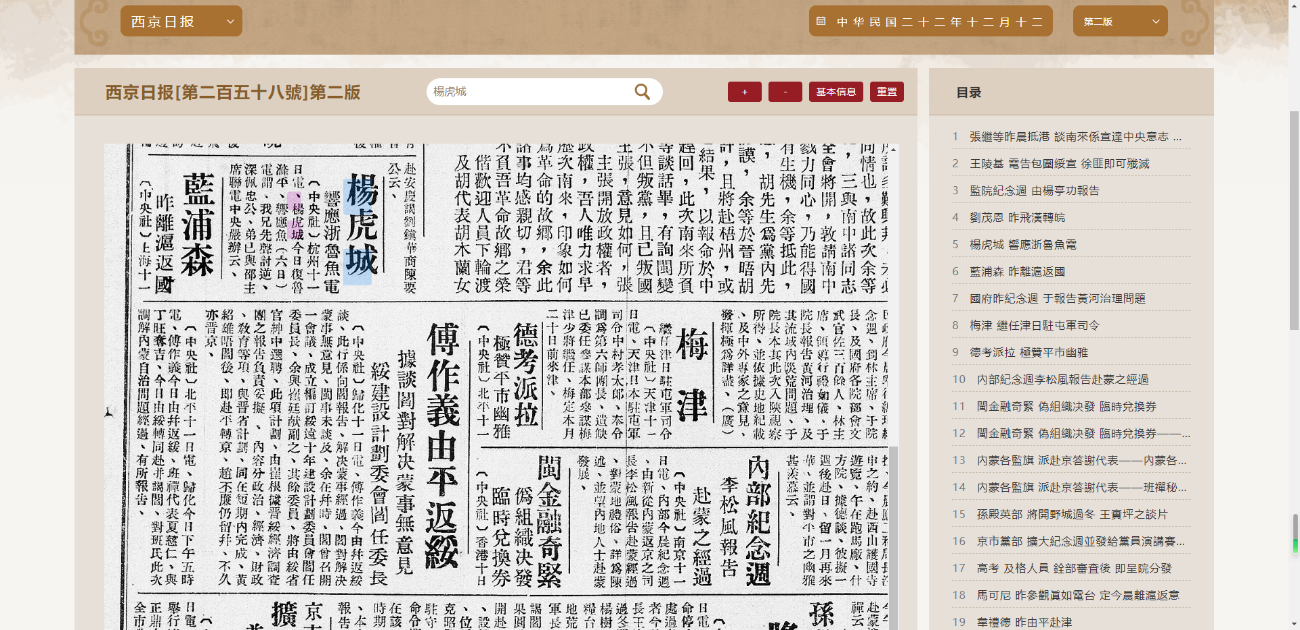
(2)数据呈现:支持对报纸原貌电子数据和元数据信息在线进行浏览,并可进行权限控制管理。
(3)资源访问:普通用户通过互联网即可进行平台访问和资源浏览。后台支持对访问权限进行控制管理。
(4)数据管理:用于数据的管理、数据上传、数据修改、数据维护,权限分配控制等。支持数据排序、数据隐藏、停用。
(5)数据可视化统计:针对数据类型进行分类统计,通过可视化图表进行呈现,让统计数据结果一目了然。
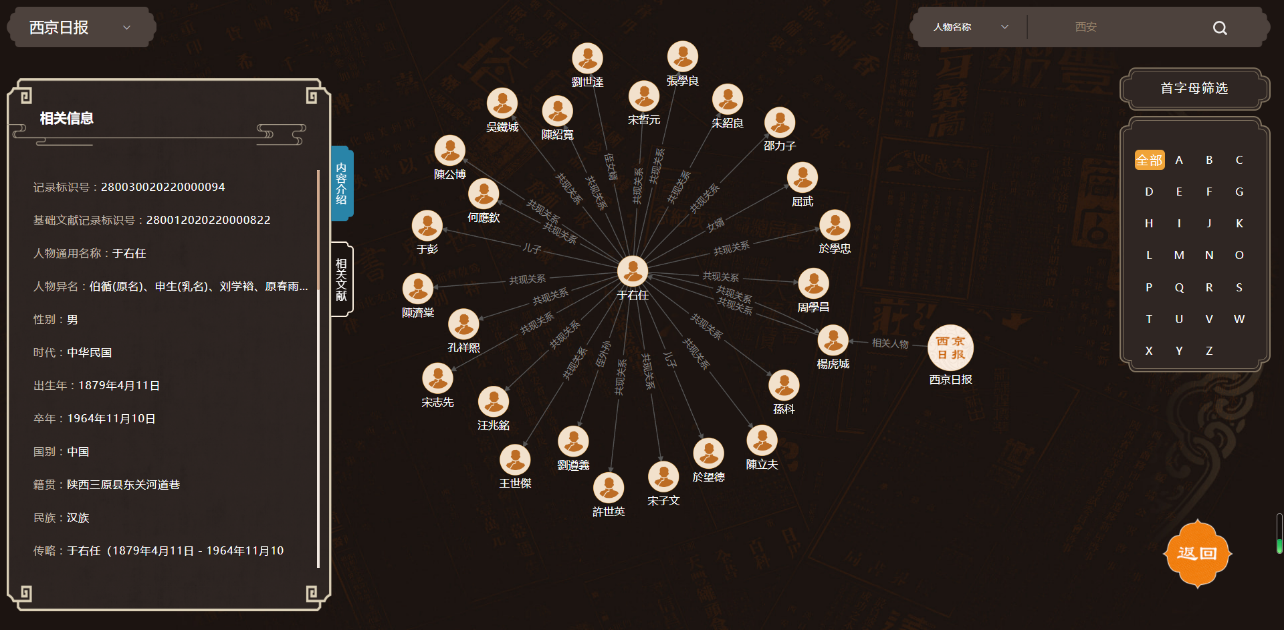
(6)知识图谱交互展示:多维度可交互的知识图谱展示、细粒度文献关联展示。
(7)数据表导出:支持字段信息批量导出为xlsx常用格式,利于管理员进行数据统计和信息查看。
2.技术应用
平台搭建了一个基于知识图谱的智能搜索系统,运用了多种先进技术,包括Neo4j数据库构建知识网络、D3.js构建关系图谱、SpringBoot搭建后台服务、NLP自然语言处理、Elasticsearch高级搜索以及PDF.js搜索定位。
(1)Neo4j数据库构建知识网络
Neo4j是一款图形数据库,与传统的关系型数据库相比,其具有更高的效率和灵活性。通过Neo4j将数据以节点和关系的形式存储,构建了一个复杂而清晰的知识网络。这种数据结构使得系统能够更加直观地理解实体之间的关联关系,从而为用户提供更加准确的搜索结果。
(2)D3.js构建关系图谱
D3.js是一个强大的数据可视化库,能够将数据转化为动态、交互式的图形展示。利用D3.js构建了一个直观清晰的关系图谱,将知识网络中的实体和关系以图形的方式展现出来。这种可视化方式使用户能够更直观地理解和浏览知识网络,从而提升了用户体验和搜索效率。
(3)SpringBoot搭建后台服务
SpringBoot是一个快速开发框架,能够极大简化Java应用程序的开发过程。通过SpringBoot,快速搭建一个稳定、高效的后台服务,实现数据的处理和业务逻辑的管理。这为系统的稳定运行提供了有力支持,同时也为后续的功能扩展和优化提供了便利。
(4)NLP自然语言处理
自然语言处理是人工智能领域的一个重要分支,其应用范围涵盖了文本分析、语音识别、机器翻译等多个方面。平台运用了NLP技术对用户输入的自然语言进行处理和分析,实现了智能搜索和语义理解的功能。这使得系统能够更好地理解用户的意图,并提供更加准确的搜索结果,从而提升了系统的智能化水平。
(5)Elasticsearch高级搜索
Elasticsearch是一个强大的分布式搜索引擎,能够快速地实现复杂的搜索和分析功能。在平台利用Elasticsearch实现了高级搜索功能,包括全文检索、模糊搜索、聚合分析等,为用户提供了高效、准确的信息检索服务,极大提升了系统的实用性和用户满意度。
(6)PDF.js搜索定位
PDF.js是一个基于JavaScript的PDF阅读器,能够在Web端实现对PDF文件的展示和操作。平台利用PDF.js实现了PDF文件的搜索定位功能,使用户能够快速定位到关键信息所在的位置。这一功能不仅提高了文档检索的效率和准确度,同时也丰富了系统的功能和用户体验。
通过运用以上多种先进技术,平台构建了一个功能强大、性能优越的智能搜索系统。该系统不仅能够有效地获取和理解信息,还能够为用户提供准确、高效的搜索服务。
(三)项目运行管理
1.平台运行:平台部署在商业云服务器,可通过互联网进行对外开放和管理。
2.用户访问:用户可通过发布的网络地址进行平台内容访问,同时平台后台支持数据访问权限控制和管理。
3.数据管理:通过对象数据采集、批量上传、知识数据提取标引、元数据著录、数据库后台进行数据的新增、修改、删除、查找以及备份等,最终形成可交付数据。
4.数据安全:支持数据权限控制管理、数据备份。可实现内部网、外网重点网段的隔离控制。支持用户角色权限分配、支持操作日志管理监控。
5.平台推广:通过官方公众号、宣传展板、门户站点、新媒体等途径进行宣传和推广。
(四)项目建设资金及日常运营维护资金投入
项目建设资金及经费来源:项目分期建设完成,一期建设资金225万元,完成15万条数据标引;二期建设资金150万元,完成10万条数据标引。项目经费来源于中央财政补助。
日常运营维护资金投入:为确保系统稳定及用户体系的流畅性该系统租用商业云服务器和存储,日常维护费用由陕西省图书馆系统运营费中支出。
平台建设采用统一的国家标准,并充分利用先进的数字交互技术,自上线以来,满足了读者多样化的文化需求,改变了群众获取文化资源的方式,为人民群众获取信息提供了更多便利。同时,基于互联网数据库平台的信息传播扩大了馆藏文献资源的服务范围,提升公共文化信息资源的利用率,数据管理更加高效和便捷,更加强了公共文化资源的信息共享。
(一)知识图谱构建关联
项目通过国内领先知识图谱技术揭示文献颗粒化关系成果;细粒度文献内容碎片化标引与抽取,原版关联文献在线浏览呈现。
(二)深度挖掘知识内容
知识颗粒化内容深度挖掘,采用互联网UI交互技术呈现多维度关系。
(三)数据制作标准统一规范
数据制作严格参照国家图书馆《智慧图书馆知识资源数据建设指南》进行规范建设,统一字段、统一标准。
(四)数据检索结果高亮显示
关键词检索能够高亮显示检索信息,检索结果支持自动统计。
(五)文献内容关联展示
相关文献可查看当前碎片化关联文章内容,也可查看原貌。
(一)创新经验
项目运用数据库平台、知识谱图谱构建与交互技术,以其先进性、开放性和便捷性,在创新大众文化服务中寻找到了突破点,促进了地方文献资源的发展以及服务模式的升级转型,对于促进地方文献高效利用,提高公共文化资源的利用率起到了重要作用。
(二)借鉴价值
元数据建设参照《智慧图书馆知识资源数据建设指南》规范制作,在平台应用发布同时数据完整导入全国智慧图书馆体系建设陕西基础支撑平台,便于国家对细粒度文献资源的统一收割和管理,保证数据的互通性和共享性。
在资源应用方面,通过互联网、交互式数据库展示平台进行资源应用服务,读者仅需访问平台站点即可使用陕西省图书馆民国报纸知识资源细颗粒度文献数字化平台服务,并能够支持大规模数据简体、繁体检索服务。
项目建设充分利用知识图谱技术,通过对文献的深度解析和关联,实现信息的精细化分类和整合,为研究者提供更为精准、全面的地方知识。该技术不仅提升了文献的检索效率,还促进了地方文献的高效利用,对地方文献资源的挖掘和利用具有深远价值。
地址:北京市西城区文津街7号 国家图书馆古籍馆
邮编:100034
服务咨询电话:4006006988、(+86 10)88545426
E-mail:webmaster@nlc.cn
