
一、参会情况概述
9月14日-25日,DCMI(Dublin Core Metadata Initiative)都柏林核心元数据年会召开,年会以视频方式举行,我馆员工周笑盈以视频连线形式参加了本次会议。参加会议的还有来自美国、德国、芬兰、加拿大、以色列、日本、英国、泰国、南非、肯尼亚、中国的五十余位科研工作者。
国家图书馆受邀在“数据整合和数据溯源—最佳实践演示”环节做了题为“多源异构资源的语义挖掘与语义组织研究与实践”的专题报告,分享了国家数字图书馆在数字资源语义整合方面的实践经验,与与会专家进行了讨论,聆听了与会专家的发言,进一步了解到元数据的深度语义描述、国际图像互操作、自动主题标引、数字资源整合经验与实践等国际元数据研究的热点和趋势。
都柏林核心元数据集(Dublin Core,简称DC)是近年来资源描述的重要规范,都柏林核心元数据倡议(Dublin Core Metadata Initiative,简称DCMI)是一个开放性的组织,支持元数据设计创新和跨领域元数据实践,2020年是DCMI组织成立25周年,2020都柏林核心元数据年会旨在分享各国图书馆在元数据应用方面的经验,探讨未来元数据发展的方向,对拓展图书馆间的开放交流与合作具有重要意义,国家图书馆将持续关注相关技术的发展和实践应用成果,以期为国家数字图书馆的知识服务能力提升和智慧图书馆建设做出更多贡献。
二、会议热点话题
2020DCMI年会主要分为主旨报告(keynote)、最佳实践展示(Best Practice Presentation)、专题小组(Panel)、教程(Tutorial)四个环节。
早期都柏林核心研讨会和会议的联合发起人斯图尔特·韦贝尔发表了题为《2020年愿景:对四分之一世纪元数据的思考》的主旨报告,回顾了过去25年元数据的发展历程,并为未来元数据向着语义化和开放化方向发展进行了展望。
根据参会获取的第一手资料,从两个方面归纳了2020DCMI年会的研究热点。
(1)图像资源的深度语义描述
图像资源的深度语义描述是为解决文化资源数字化图像难以被发现、再利用、引用、交换、比较分析等难题,确保图像存储的互操作性和可获取性。
会议选取了Synaptica公司、台湾数位图书馆的木牍字典项目和国际图像互操作框架IIIF做了介绍。
Synaptica公司使用了“添加标签”的方式对资源进行整合,对资源添加属性标签(如图1),在资源浏览页面底部可以点击相关标签实现wiki内容的自动跳转(图2)。
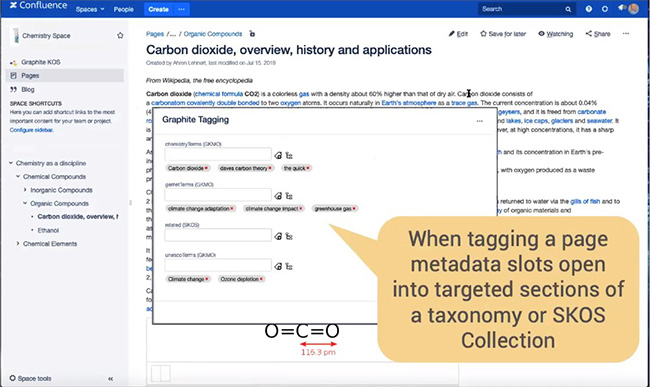
图1
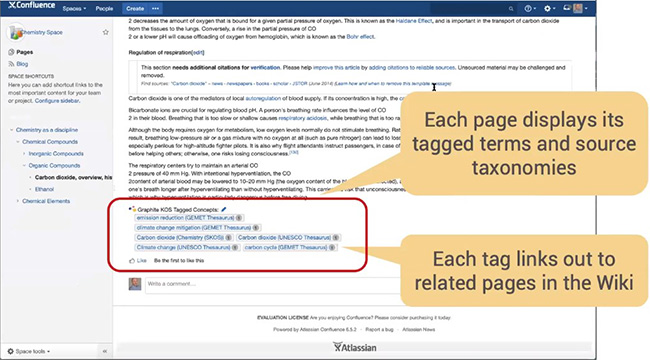
图2
台湾历史数位图书馆对馆藏木牍作品进行本体标引,共标引了848个实体,1046张图片,生成了21265个数据本体,数据库开发了元数据检索和跨库查询功能,可以实现跨机构的片段检索、资源调取和展示。

图3
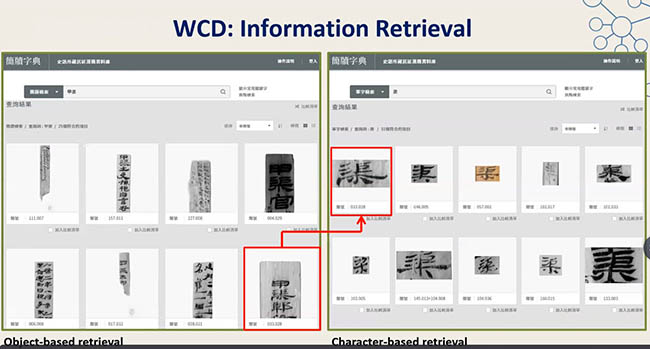
图4
国际图像互操作框架IIIF定义了若干个系统间用于交换数据的接口(API),它们能用于描述和传递图像及关于图像的结构化数据。首先通过光学字符识别(OCR)和自然语言处理进行内容的标记,对图像资源进行内容提取(如图5-7),依据本体模型进行标引内容的分类(如图8-10),将描述的元数据信息转化为JSON-LD 文档,通过关联数据技术,可以实现不同数据库片段资源的调取和资源的重新拼接。

图5
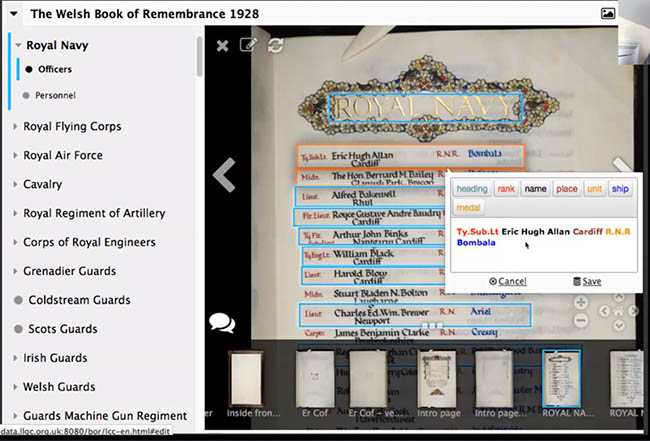
图6

图7
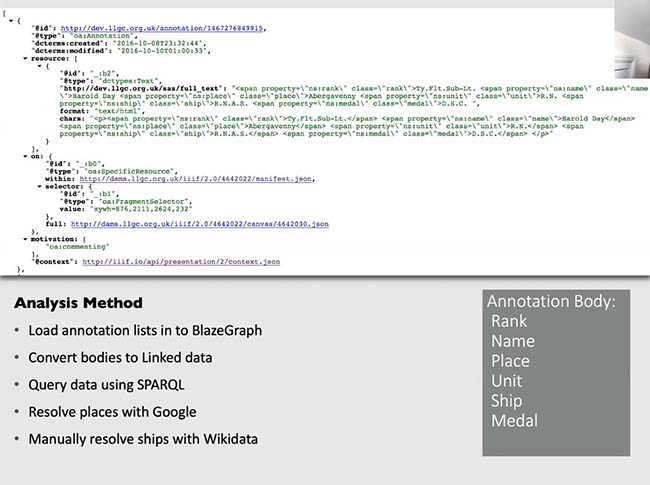
图8
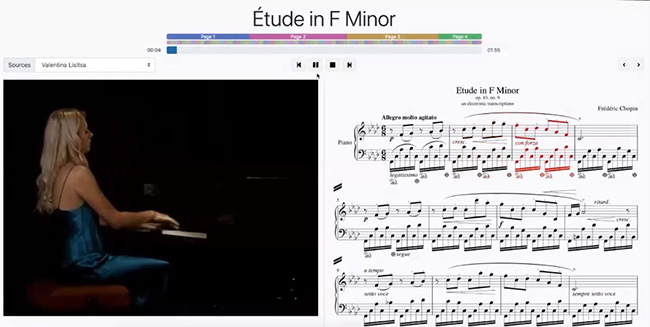
图9

图10
(2)自动主题标引与机器学习
会议主要选取了芬兰国家图书馆的Annif——自动主题标引和分类工具做介绍。

图11
Annif工具的整体工作机理为:在语料库中上载大量的词汇表,生成机器自动学习的语料模型,从而自动为读者提供主题分析和推荐资源。
实现效果如下图,输入一段文字“那只敏捷的棕色狐狸跳过了那条懒狗”,annif系统自动提取关键词标签“红色狐狸”、“狗”、“懒惰”、“棕色”、“三级跳”,并依据这些关键词提供相关的资源。图13展示的是在annif系统中粘贴进一段CNN的新闻稿,系统自动分析出了“推荐主题(suggested subjects)”,例如“银行”、“银行的历史”、“银行规章”、“发展银行”、“中心银行”、“英国”、“银行会计”等相关主题。
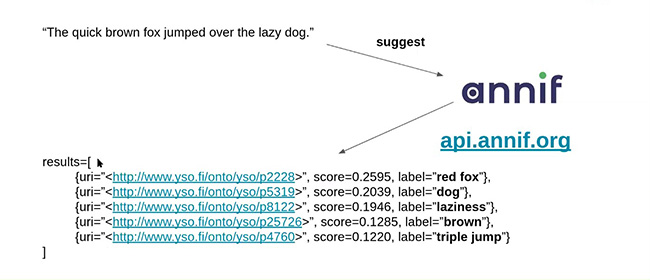
图12
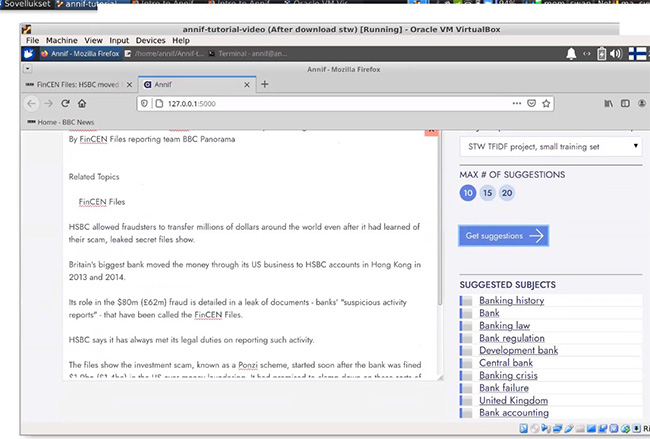
图13
三、数字图书馆本体标引流程设计
结合会议内容,初步设计了简单的本体标引流程:
(1)将所有元数据资源转化为RDF描述格式。
(2)设计本体模型,例如作者(author)、提供商(contributor)、出版商(publisher),为本体下的实体赋值。
(3)为每一个本体赋予URI标识。
(4)基于本体模型标引对象数据,包括古籍、电子书、杂志、报纸、视频、图片等资源对象,并依据本体模型关联实体和数据。
(5)提供开放数据(open data)或权限控制(authority control),通过API接口对接第三方数据。
例如人名规范库:

图14
(6)资源片段标引,将古籍或电子书资源的内容片段进行文本提取,并保存为不同的资源片段,通过对片段进行元数据编目,实现对资源片段细节内容的检索。

图15
(7)资源内容分析,将古籍、电子书、视频资源的文本内容进行提取后,进行文本统计分析,包括词云、词频统计和标注的实体清单。
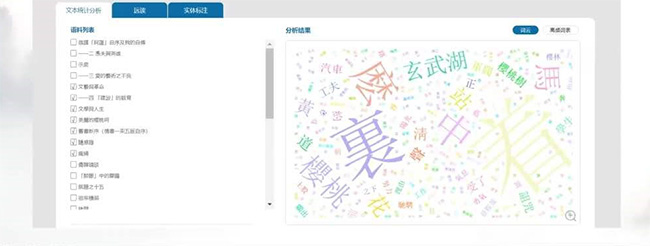
图16
(8)制作人物关系图谱,根据标注的实体和实体关系,生成人物关系图谱,并根据人物实体关联馆藏资源。
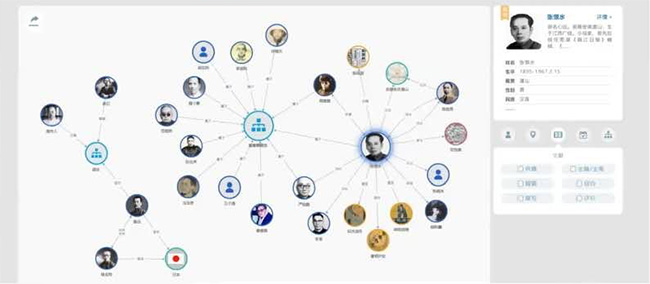
图17
四、国家图书馆专题报告
国家图书馆受邀在“数据整合和数据溯源—最佳实践演示”环节做了题为“多源异构资源的语义挖掘与语义组织研究与实践”的专题报告,分享了国家数字图书馆在数字资源语义整合方面的实践经验。
在开篇介绍了国家图书馆概况和国家数字图书馆概况,主体部分从数字资源语义挖掘与语义组织的三个流程:本体标引、关联数据、专题聚合出发介绍中国国家图书馆代表性实践成果。
本体标引环节,以国家数字图书馆的数字化家谱标引项目和近代报纸资料库项目为例,介绍数字文化遗产资源的深层语义标引技术和可视化模型。关联数据环节,以多媒体资源——国图公开课视频为例介绍视频元数据的语义转化和关联数据发布,并简要介绍关联数据公开平台。专题聚合环节,以基于新浪微博的社交媒体专题聚合和中华人民共和国大事记馆藏资源聚合介绍国家数字图书馆的资源聚合实践。最后,对目前多源异构资源的语义挖掘与语义组织研究存在的问题与挑战进行分析。
地址:北京市海淀区中关村南大街33号
邮编:100081
服务咨询电话:4006006988、(+86 10)88545426
E-mail:webmaster@nlc.cn
